docker部署ELK日志监控
发布时间丨2022-08-19 10:03:09作者丨zhaomeng浏览丨15
ELK 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一个搜索和分析引擎。
Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等存储库中。
Filebeat 获取每个服务器的日志并推送到es(小规模可以替代logstash)
Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
第一步:filebeat安装到ubuntu20.4
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.2.0-amd64.deb
sudo dpkg -i filebeat-7.2.0-amd64.deb
配置input安装成功之后,配置文件的路经在/etc/filebeat/filebeat.yml,直接使用vim filebeat.yml .修改paths的值为日志路径

#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /mnt/data/wendalog/*.log
#- c:\programdata\elasticsearch\logs\*
配置output.elasticsearch
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
运行filebeat:

sudo filebeat -e -c filebeat.yml
第二步:安装elasticsearch及es-head
docker安装ES
下载镜像:
docker pull elasticsearch:7.4.2
创建挂载数据目录卷并写入初始文件,及目录权限获取
mkdir -p /mnt/data/elasticsearch/config # 在文件夹下创建es的config文件夹,将docker中es的配置挂载在外部,当我们在linux虚拟机中修改es的配置文件时,就会同时修改docker中的es的配置
mkdir -p /mnt/data/elasticsearch/data #在文件夹下创建es的data文件夹
echo "http.host: 0.0.0.0" >> /mnt/data/elasticsearch/config/elasticsearch.yml # [http.host:0.0.0.0]允许任何远程机器访问es,并将其写入es的配置文件中
chmod -R 777 /mnt/data/elasticsearch/ # 保证权限问题
创建容器并运行
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \
-v /mnt/data/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mnt/data/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mnt/data/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
# docker run --name elasticsearch 创建一个es容器并起一个名字;
# -p 9200:9200 将linux的9200端口映射到docker容器的9200端口,用来给es发送http请求
# -p 9300:9300 9300是es在分布式集群状态下节点之间的通信端口 \ 换行符
# -e 指定一个参数,当前es以单节点模式运行
# *注意,ES_JAVA_OPTS非常重要,指定开发时es运行时的最小和最大内存占用为512M和512M,否则就会占用全部可用内存
# -v 挂载命令,将虚拟机中的路径和docker中的路径进行关联
# -d 后台启动服务
安装成功之后

浏览器访问本地9200端口,出现如下的页面代表安装成功!
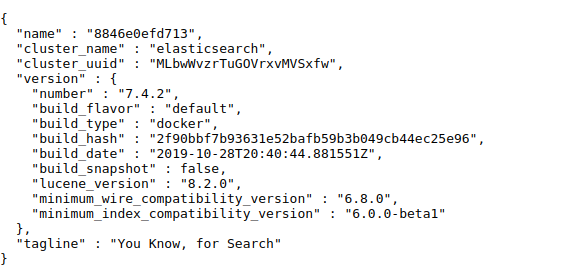
elasticsearch的head插件的可以观察es的服务器状态,也可以查询数据,可视化界面非常方便,那么如何在docker环境下安装elasticsearch的head插件呢,下面将详细介绍:
修改elasticsearch配置文件,添加如下代码:不加如下 的代码es-head不能跨域链接到es!
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
下载镜像
docker pull mobz/elasticsearch-head:5
创建容器
docker run -d --name es-head -p 9100:9100 mobz/elasticsearch-head:5
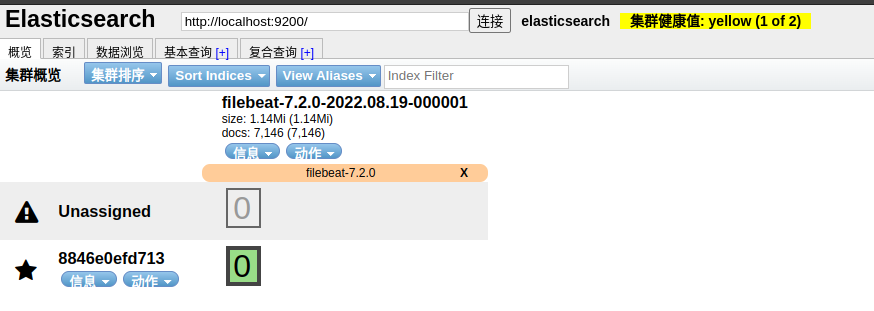
查看是否安装成功,出现下图就代表配置及安装完成,浏览器输入本地9100端口:
第三步:docker安装kibana,可视化查看es的数据
下载镜像这里需要保持kibana和es的版本一致否则kibana报错如下:我的es和kibana版本都是7.4.2
下载镜像:
sudo docker pull kibana:7.4.2
制作容器:
sudo docker run --name kibana --restart=always -e ELASTICSEARCH_HOSTS=自己的esip地址:9200 -p 5601:5601 -d kibana:7.4.2
进入容器修改配置文件es主机IP以及配置中文显示

kibana.yml配置文件如下:
#
# ** THIS IS AN AUTO-GENERATED FILE **
#
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://自己的IP:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
#设置kibana中文示
i18n.locale: "zh-CN"
访问浏览器的5601端口显示如下代表程序运行成功!
点击配置(左侧最后一个图标)kibana的es索引模式配置索引,获取es的日志文件信息
创建索引 ,索引和es中的一致,及kibana通过配置的索引获取es的数据
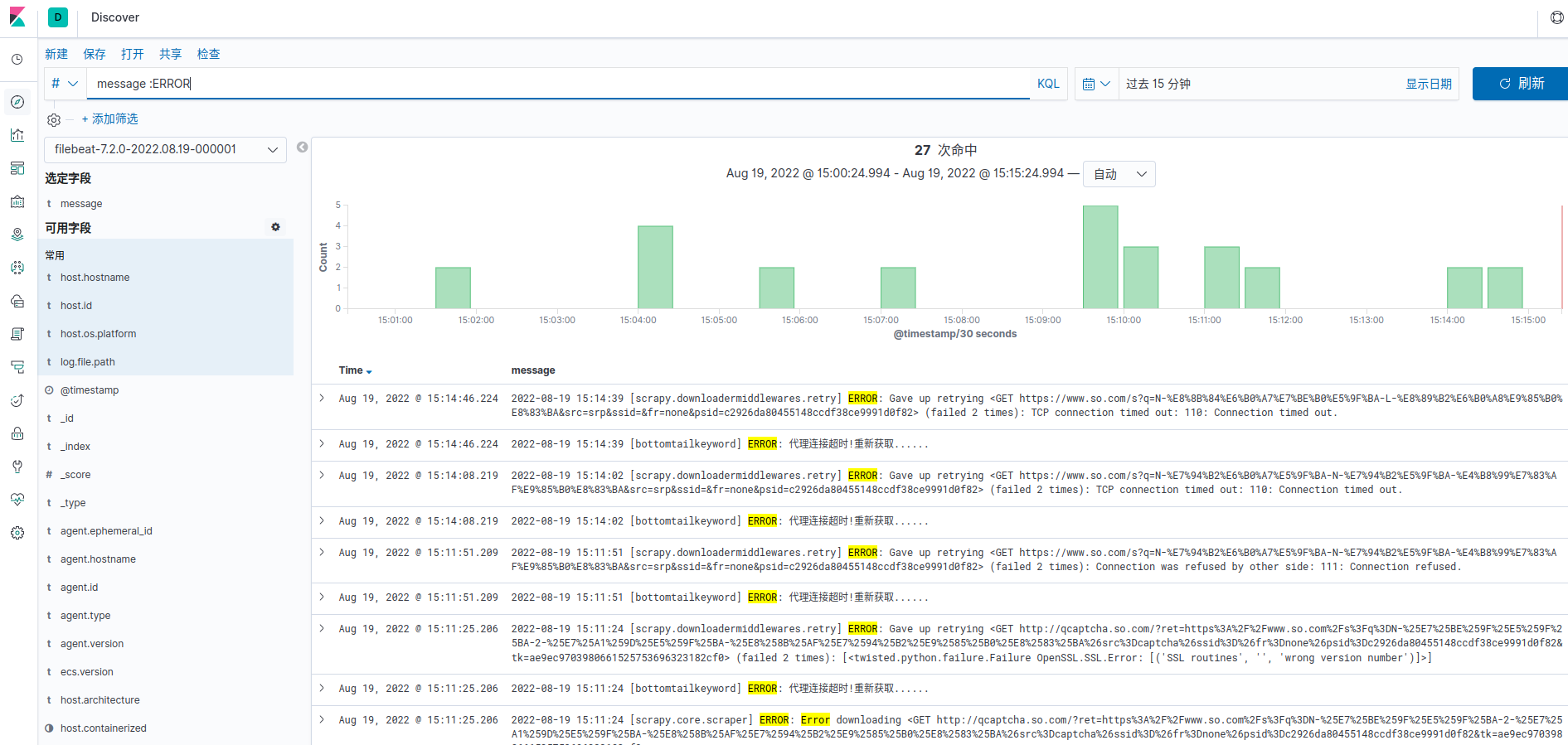
选择下一步配置完成之后进入discover配置
配置索引及筛选message中包含的ERROR字段的日志
kibana报错Data too large不能够正常运行,解决方法如下:
docker部署了kibana,正常运行,但是突然搜索的时候报错不能够链接到es的集群问题,思虑过后,查看docker的kibana的日志文件,docker logs id ,发现报如下错误: [circuit_breaking_exception] [parent] Data too large, data for [<http_request>,是因为数据量太大导致内存不足,因该是创建容器的时候设置了最大和最小的内存,因此删除容器重新制作容器,内错最大和最小都设置成512M, -e ES_JAVA_OPTS="-Xms512m -Xmx512m",发现成功可以打开kibana